
Kubernetes, seguro que es una de las palabras que más se está buscando ahora mismo en el mundo de IT. Pero ¿cuánta gente sabe realmente qué es y cómo funciona? Y lo más importante ¿cuándo hay que recurrir a ella?
Apúntate al webinar gratis sobre Kubernetes gestionado
Kubernetes es un sistema de gestión o de orquestación de contenedores. Suena fácil, ¿no? Mira este esquema si no te queda claro:
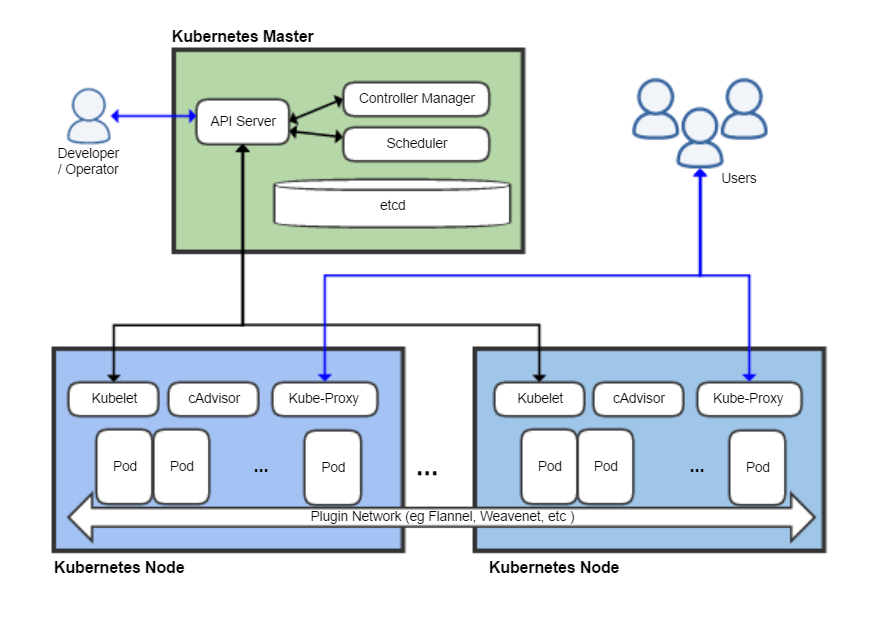
¿A que ahora sí que lo entiendes? 😅
A mi me costó entenderlo un tiempo debido a la gran cantidad de información que hay sobre ello y de que muchas empresas están intentando adaptarlo a su negocio y meten la definición que les encaja en su producto.
¿Qué significa que sea un «sistema de orquestación»? Básicamente Kubernetes (o k8s como también se le denomina) lo que hace es encargarse de las tareas de descargar y hacer accesibles desde Internet los distintos contenedores que queremos desplegar en un sistema, que, aunque hice que pareciese sencillo en el anterior post sobre Docker, una vez que tengas un volumen «interesante» de servicios a desplegar es una tarea cuanto menos tediosa.
Si bien Docker tiene herramientas adicionales como Docker Composer que nos ayudan en el despliegue de varios contenedores, se queda corto en el sentido de «vale, ya tengo esto en contenedores, ahora quiero además xxx«, lo cual puede suponer desplegarlo en varios servidores, además de meter varios scripts caseros de por medio, multiplicando el trabajo que ello conlleva. Además igual queremos otras cosas como:
- Si ya tengo una replicación de bases de datos, me gustaría que estuviesen en servidores distintos.
- Además aquí tengo este hardware específico con más RAM/CPU/GPU/Conectividad en el que tengo que ejecutar este software X.
- Y claro, hay que controlar que los servicios estén activos.
- Por supuesto que si el servicio empieza a tener carga hay que hacer que escale.
Son cosas realmente básicas; algo habitual en el día a día de sistemas. ¿Y cómo hace Kubernetes todo eso? Abstrayéndose de todo y con una curva de aprendizaje muy… interesante.
Su gran baza: que es libre y estándar
Si bien hasta ahora muchos proveedores de servicios en el Cloud ya habían comercializado en mayor o menor medida sistemas para desplegar nuestra aplicación de forma «containerizada», el problema era ese: si aprendías a usar un sistema te atabas a ese proveedor. Lo que ha hecho Kubernetes es ofrecer un sistema de forma que en cualquier proveedor de Cloud el despliegue es similar, y te da lo mismo estar con el proveedor A, G, M o S ya que todos ellos dan su propio «sabor» de Kubernetes (GKE, EKS, AKS…).
Es más, es posible llegar a hacer mezclas de distintos proveedores Cloud, con equipos dedicados físicos, etc. ya que además Kubernetes es software Open Source y podemos instalarlo tanto en un clúster de varios miles de euros de «hierro» como en una Raspberry PI o en un portátil para hacer pruebas.
Esto se traduce en que a nivel de usuario tenemos lo que siempre hemos querido y es no atarnos a un único proveedor. No solo a nivel «político» de «tenemos contrato con este proveedor» si no que podríamos llegar a tener un sistema de alta disponibilidad corriendo en distintos proveedores.
A nosotros como proveedor de servicios en la nube esto nos supone el poder entrar en el juego de los grandes y poder hacer una oferta atractiva al usuario final, que no tiene que aprender un nuevo sistema de gestión de paquetes/contenedores. Todo el mundo gana.
Apúntate al webinar gratis sobre Kubernetes gestionado
Orígenes en la Gran G.
Al igual que muchas otras herramientas, Kubernetes se empieza a formar en Google. La forma de trabajar y la inmensidad de la infraestructura de Google hace que cualquier servidor de sus data centers tenga que poder albergar cualquier servicio (y en Google no son pocos). Para ello construyeron un software que gestionaba sus contenedores. A este software la llamaron Borg. En el universo de Star Trek, el Colectivo Borg es una «raza» de seres con una mente de tipo colmena, en que todos trabajan para el mismo fin y cada individuo es reemplazable.
Años después y partiendo de esta base apareció Kubernetes, en el que han participado varios ingenieros que anteriormente trabajaron en Borg.
Arquitectura y YAML
La forma que tiene kubernetes de hacer que funcione en cualquier tipo de proveedor Cloud es la de abstraer la infraestructura del proveedor, generando la suya propia. Además, excepto en entornos de desarrollo, siempre que hablamos de Kubernetes hablamos de un clúster de Kubernetes.
Y aquí es donde se empieza a complicar todo, ya que tenemos:
- Nodos controlplane, son los encargados de controlar el estado del clúster, utilizan una base de datos distribuida llamada ETCD que se encarga de consensuar, entre los distintos nodos del clúster, el estado del mismo.
- Nodos worker, que son los que correrán nuestras cargas de trabajo.
- Pods, el pod es una agrupación de contenedores. A Kubernetes no le subimos un Dockerfile si no que le decimos que en este o aquel pod tiene que ejecutar esta o aquella imagen de Docker, y no tiene por qué ser una única imagen si no varias por pod.
- Además estos pods tienen réplicas, podemos elegir cuántos pods de cada queremos, y cómo los queremos tener distribuidos.
- También tendremos servicios en los que definiremos cómo tienen que trabajar nuestra aplicación y nuestros despliegues.
- Por supuesto la red es una cosa más a abstraer, por ello mismo todos los pods corren sobre una red SD-WAN (que puede tener varios niveles): las IPs de los workers y de los pods son totalmente distintas.
- La forma de hacer que el tráfico externo llegue a nuestros contenedores también es algo aséptico al proveedor (aquí tenemos varias formas de hacer que el tráfico llegue desde el exterior): LoadBalancers, Ingress, NodePort, ClusterIp…
- Y… un montón de elementos más, que no son más que una forma de abstraernos de la infraestructura (Kubernetes no sabe ni de Docker, ni de servidores, ni de VLAN, ni de nada) y que cuando tienes que «aprender a desaprender lo aprendido» que diría Berri Txarrak. El cambio de paradigma es tal que es muy complicado el ponerse a trabajar desde cero con un clúster de Kubernetes.
La forma y flujo de trabajo en que interactuamos con un clúster es mediante archivos YAML, olvídate de ventanas, formularios y pantallas.
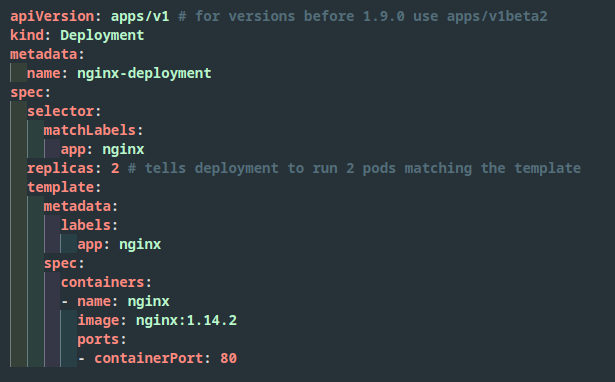
En nuestros archivos YAML definimos nuestra arquitectura y luego mediante una herramienta tipo kubectl (por lo general en línea de comandos), le decimos al clúster que aplique la configuración que queremos. Una vez enviada esta configuración a Kubernetes, éste se encargará de estar continuamente revisando que se cumpla lo que hemos mandado.
Haciendo un símil con la imagen que adorna la cabecera, podríamos decir que estos archivos YAML son nuestra partitura que se la pasamos a Kubernetes (el director de la orquesta) y éste la hace sonar, independientemente de si el primer violín hoy es el mismo que ayer o si está en la ópera de Sidney o en la de Londres y si está tocando la banda sonora de una película Christopher Nolan, una ópera del sigo XIX o el Requiem de Mozart.
Ya que el despliegue de ciertas aplicaciones se puede complicar mucho, tenemos distintas herramientas como los operadores o las charts de Helm que nos ayudan en el despliegue de software ya preestablecido, como si fuese una especie de gestor de paquetes.
Podéis ver un ejemplo de un WordPress desplegado en Kubernetes en este repositorio de Github de IBM, con un esquema del mismo, un poco más complicado de lo habitual para un «simple» WordPress ¿no? Lo cual nos lleva a la siguiente pregunta…
¿Para quién es?
Es la pregunta del millón de dólares. ¿Es Kubernetes para mí? Kubernetes es un sistema muy complicado, en el que hacer debug es muy muy complejo debido a todas las capas de abstracción que tiene (el hacer «sencilla» la infraestructura a tan alto nivel tiene un coste). Hay que tener muy claro el problema que tenemos antes de intentar lanzarle tecnologías para ver si se soluciona.
Además para la integración en nuestro sistema o aplicación hay que tener un gran conocimiento interno de cómo funciona, sus dependencias, etc. así como además de tenerlo o ser capaz de tenerlo funcionando en contenedores, que no siempre es posible.
Pero al igual que complica ciertas cosas, hace más sencillas otras. ¿Quieres desplegar un clúster de ElasticSearch? Con un comando es suficiente. ¿Lo que necesitas es un PostgreSQL replicado y con copias de seguridad automáticas? Más sencillo que nunca.
Algunas curiosidades (fusiladas de la Wikipedia y de otros sitios)

- Se suele estilizar «k8s», esto es similar a cuando se escribe «i18n» cuando se habla de «internalization», es decir, para evitar tener que escribir la palabra entera; simplemente hay 8 letras entre la K y la S.
- El nombre Kubernetes es griego (κυβερνήτης) y viene asignificar «timón». Además es la raíz etimológica de «cibernética».
- De hecho el timón de su logotipo tiene 7 brazos como homenaje al personaje «Seven of Nine» de la Serie Star Trek: Voyager. Seven of Nine es una ex-Borg e internamente en Google era «Project 7«, igual que los ingenieros que lo desarrollan.
- No, no puedes decir Kubernetes y solucionar todos tus problemas.
Inscríbete ahora al webinar gratis sobre Kubernetes gestionado



{kind=link}
3 Comentarios
Puedes enviar comentarios en este post.
[…] servicios de datos para Big Data, Inteligencia Artificial e Internet de las Cosas (IoT) sobre plataformas Kubernetes como la de Sarenet. Es una herramienta compatible con nubes públicas o privadas, permanentemente monitorizada, […]
Lainotik: genera valor para tu negocio con tus datos | Blog Sarenet 5 años ago
[…] las barreras que impedían a muchas empresas y países acceder a la tecnología. De hecho, si bien Kubernetes ha generado grandes dudas, numerosas fábricas de nuestro entorno ya lo […]
Nos visita Bart Farrell, líder de Data on Kubernetes | Blog Sarenet 5 años ago
[…] en este blog acerca de algunos de los principales avances en el ámbito del hosting: Docker y Kubernetes. Son dos tecnologías que van de la mano y que en los últimos años han pegado muy fuerte y están […]
El futuro del hosting (y II) | Blog Sarenet 4 años ago
Enviar una respuesta
No hay comentarios