
Hace poco más de un mes sufrimos en Sarevoz un fallo de unas 2 horas de duración (uno de los cortes más grandes de los últimos años), y como me encanta leer los post morterms de distintos servicios como reddit, gitlab o flickr, voy a hacer uno de lo ocurrido y explicar qué hemos hecho para solucionarlo, acompañado de una pequeña explicación de cómo funciona la infraestructura que tenemos montada para el servicio. Espero que te gusten las gráficas.
Jueves, 30 de marzo, llego a la oficina más tarde de lo habitual al estar de guardia y, al haber realizado la noche anterior una intervención en Sarevoz para actualizar los equipos de base de datos a nuevo hardware, me encuentro con que desde hace un rato Sarevoz no está funcionando correctamente: muchas llamadas no se están procesando y los trunks no están registrándose bien.
Por lo que me comentan, todo ha estado funcionando correctamente hasta las 9:00h, cuando ha empezado a fallar. Revisando los servicios, están todos arrancados y funcionando correctamente, hay conexiones hacia y desde todos los servicios y nada está dando errores evidentes; sin embargo, no está funcionando. Mirando nuestro querido Grafana es evidente.
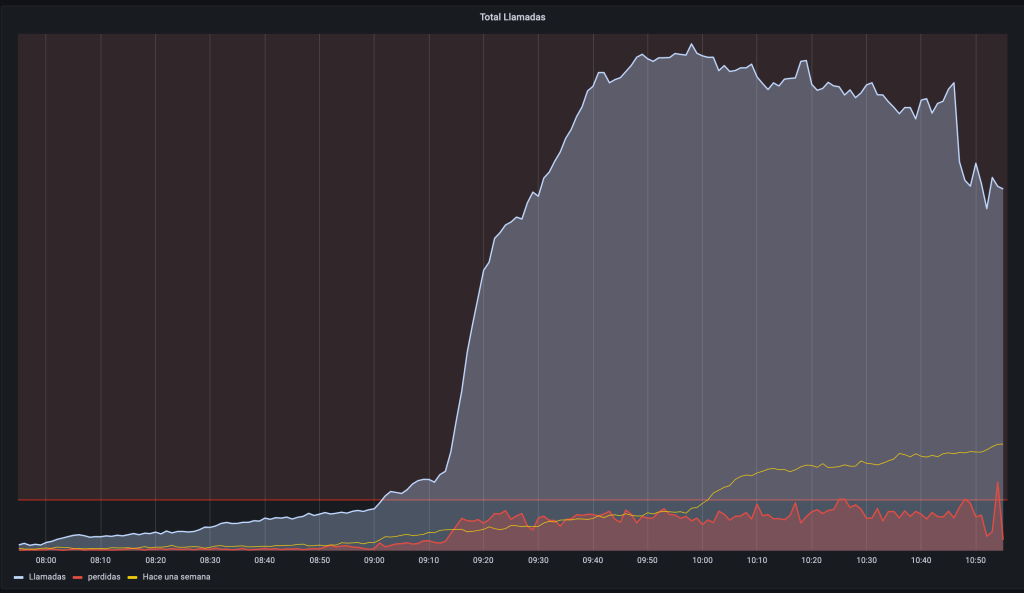
Pero si la intervención de la noche fue bien, ¿qué podía estar pasando? No hay que tener muchas luces para pensar que ese cambio fue el causante de todo ya que al revertirlo se estabilizó el servicio pero… ¿Qué hizo que fallase al día siguiente y no en el momento del cambio?
Arquitectura de Sarevoz y el cambio de la noche anterior
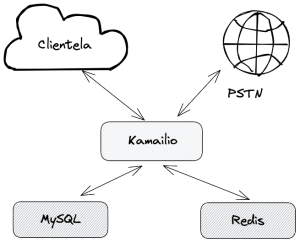
La arquitectura simplificada de Sarevoz no es muy distinta a la de una web como esta: WordPress, básicamente es una aplicación que utiliza distintas bases de datos, sólo que en vez de HTTP el protocolo que se usa para interacturar es SIP. Así que a grandes rasgos y simplificando mucho el número de servidores y flechas, centrándonos en lo que nos interesa, sería algo similar a este esquema.
Como software principal utilizamos Kamailio con distintas configuraciones y roles, el cual se apoya en varias bases de datos para hacer accounting, validar credenciales, direcciones IP, reglas de rutado, permisos, etc. Desde hace años venimos utilizando un cluster de varios nodos de Percona XtraDB para la parte de MySQL y también varios equipos con Redis para consultas de tipo key-value en las que necesitábamos más velocidad de la que nos ofrecía MySQL.
Como en cualquier proyecto vivo de IT, renovamos los equipos cada cierto tiempo y desde finales del año pasado estamos renovando la plataforma para dotarla de más capacidad, versiones más modernas de software, etc. A principios de marzo renovamos los equipos de Redis (y nadie se dio cuenta) y para finales de mes teníamos pendiente la renovación de los equipos de BBDD, así que nos pusimos al lío.
Para ello, montamos nuevos equipos en nuevo hardware más moderno (más y mejores discos duros, más y más rápida RAM, unas CPU más modernas, interfaces de red a 10G, etc.) y los unimos al cluster ya existente, donde estuvieron varios días funcionando e hicimos pruebas de rendimiento. En estas pruebas sintéticas vimos que los nuevos equipos tenían mejor rendimiento, así que dimos por bueno el paso a producción de los mismos 💪🏻.
El cambio a los nuevos equipos lo hicimos fuera de horas, a las 23:00h del día 29, y pasamos la carga de trabajo al nuevo cluster, tras hacer las pruebas correspondientes y ver que el tráfico en la plataforma era el habitual, me fui tranquilamente a la cama, sin saber lo que me esperaba al día siguiente.

El problema
El mayor tráfico de Sarevoz lo tenemos entre las 8:00h y las 20:00h, siendo hora punta de 10:00h a 13:00h (por la tarde hay menos tráfico), es la gráfica habitual que vemos tanto en correo como en red. Es decir, que se trabaja más por la mañana que por las tardes.
Todo parecía ir bien hasta las 9:00h, que es cuando el tráfico aumenta: se disparó el tiempo de registro, las llamadas no se finalizaban bien y tampoco se procesaban bien las nuevas. Una métrica que ilustra muy bien el problema es la del tiempo que tarda un REGISTER, algo que medimos desde distintos nodos de la plataforma. Lo mismo ocurría en la métrica de tiempo de progreso de las llamadas.
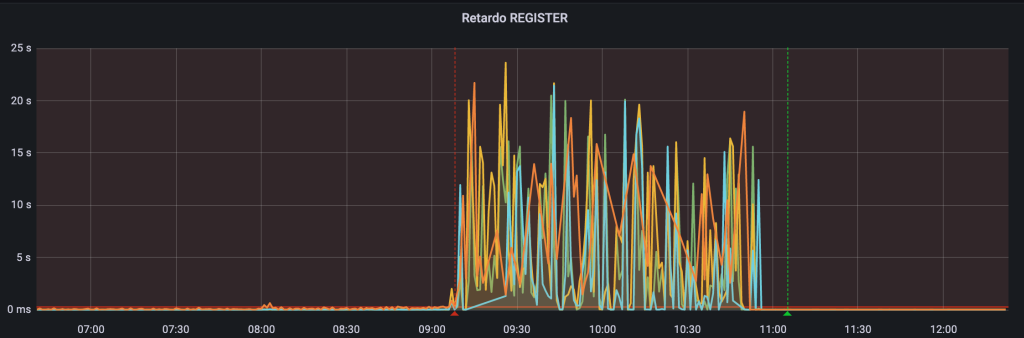
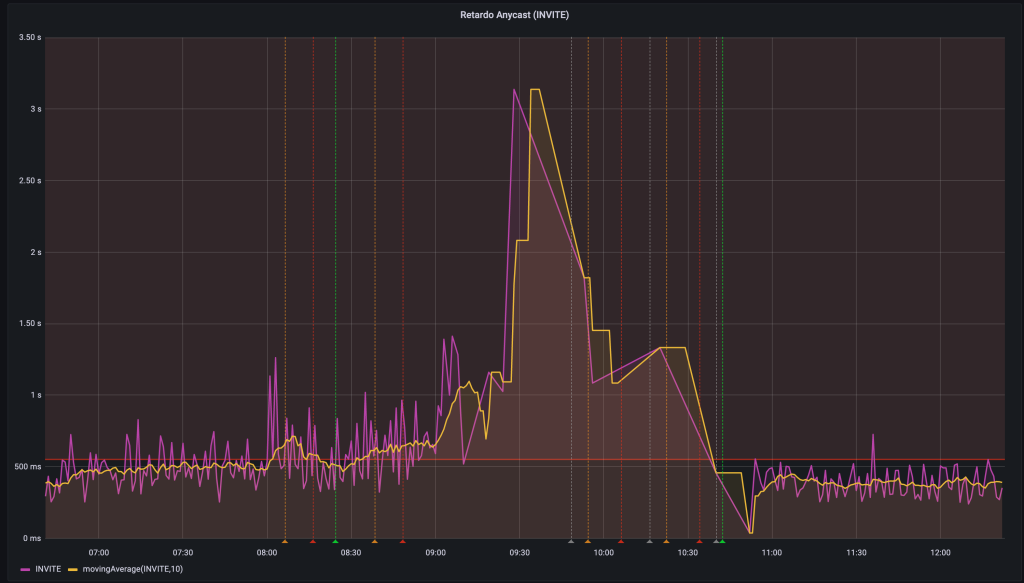
Evidentemente lo primero que sospechamos era que los nuevos equipos no estaban funcionando bien, pero no entendíamos nada, podíamos hacer cualquier consulta que respondía correctamente sin retardos. Como no sacábamos nada en claro revertimos el cambio y todo volvió a la normalidad progresivamente.
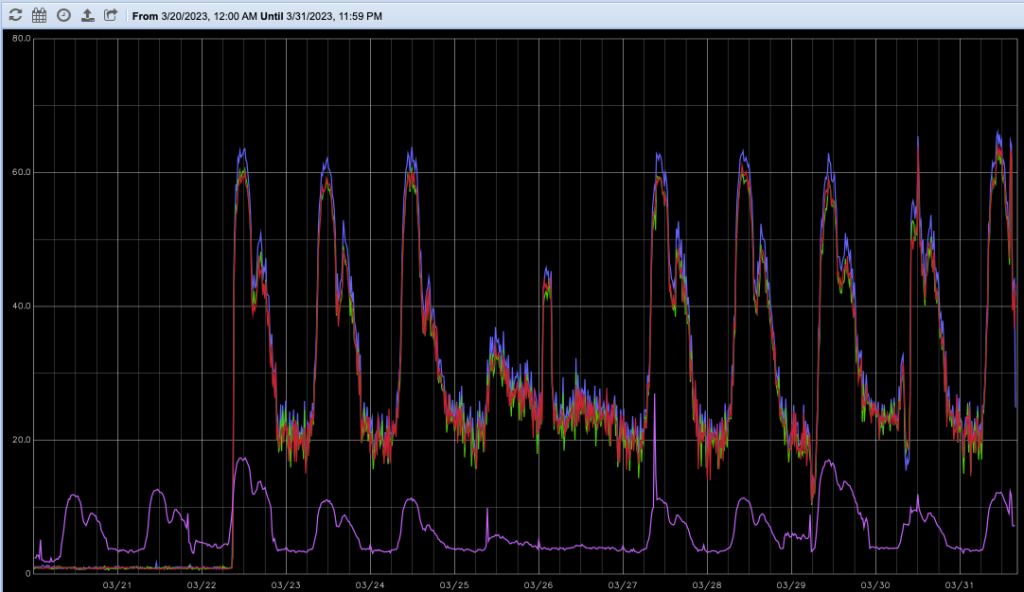
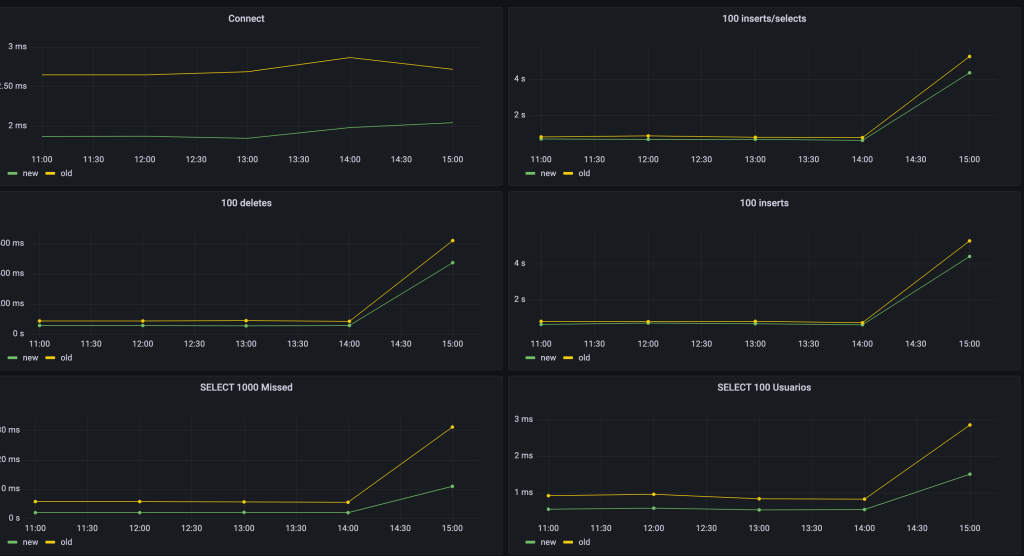
Nos pusimos a analizar todo lo relacionado con los equipos hasta que dimos con el problema: a pesar de que la versión de MySQL era prácticamente la misma (con algunos parches más), el rendimiento del disco era mucho peor en los nuevos equipos, haciendo que si bien las consultas de prueba funcionaban, para el uso en tiempo real que hace Kamailio de la base de datos, no daba el suficiente rendimiento en horas de mucha carga de llamada.
Análisis y pruebas
Como la actualización de los equipos es algo que sí o sí teníamos que hacer, nos pusimos a hacer multitud de pruebas:
- Probamos a mover una de las BBDD a los nuevos equipos: seguían funcionando bien (es más ¡se notaba el cambio de hardware y daba mejor rendimiento!)
- Probamos a cambiar el sistema operativo (los equipos viejos eran CentOS 7 y los nuevos Debian 11) por Ubuntu LTS, mismo rendimiento.
- Probamos a cambiar el sistema de archivos (los viejos eran XFS y los nuevos EXT4), mismo rendimeinto.
- Probamos distintas versiones del Kernel, opciones de montaje del sistema de archivos… Agua.
- Revisamos todos los tunables de sysctl para ver posibles diferencias… No sacamos nada en claro.
- Revisamos una y otra vez la configuración de MySQL, probando distintas opciones, sin llegar a ninguna mejora.
Al ver que no encontrábamos una causa clara, decidimos cambiar de estrategia e investigar las consultas que podían estar «haciendo daño» a la base de datos y tratar de solucionarlas.

Hicimos un muestreo de las consultas a la BBDD durante 10 minutos de uso normal y nos encontramos con esto:
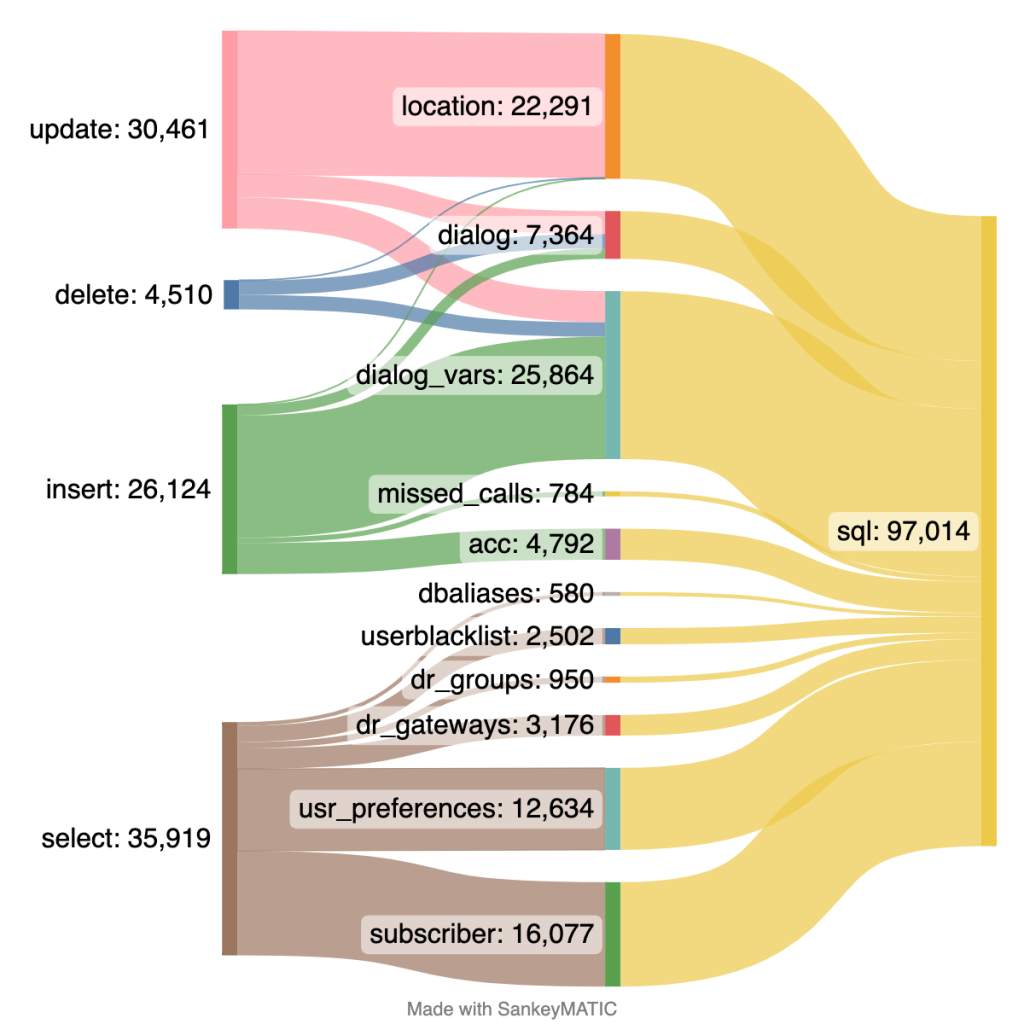
Tal y como pensábamos, casi toda la escritura la realizan dos módulos de Kamalio, el módulo location y el módulo dialog.
Location es el módulo que se encarga de mantener el registro de los sip trunks, este modulo lo tenemos configurado de forma que funciona el 100% del tiempo con lo que tiene en memoria, y vuelca a BBDD cada 60 segundos esta información para, en caso de reinicio del proceso, recargar en memoria estos registros y seguir funcionando.
Por otra parte, dialog es el módulo que se encarga de gestionar todos los parámetros de las llamadas en curso: quién llama, a dónde, cuánto tiempo lleva llamando, distintas características de la llamada… Este módulo lo tenemos configurado en modo realtime, es decir, trabaja exclusivamente contra la BBDD. Esto es así ya que utilizamos estos registros para distintas tareas, siendo una de las más importantes la gestión de riesgo y el control de consumo de los trunks, para evitar fraudes y sorpresas.
Estos datos son bastante efímeros: los registros se actualizan cada 60 segundos y los datos de las llamadas lo que dure la llamada (que no suele llegar nunca a las 3h), por lo que no necesitamos ni almacenar el histórico ni una gran persistencia. Es por ello que empezamos a mirar al otro motor que utilizamos en Sarevoz para BBDD: Redis.
¿Y si pasamos a Redis?

No es casualidad que Kamailio utilice MySQL (o PostgreSQL o cualquier otro motor de SQL) como base de datos principal, ya que las consultas que utiliza y por la forma de trabajar necesita que sean relacionales, algo que las BBDD de tipo key-value como memcached o Redis no soportan (es precisamente su principal feature). Sin embargo desde hace unos años hay un nuevo módulo en Kamailio llamado DB_REDIS, este módulo tiene definiciones de lo que serían las tablas de SQL internamente, de forma que es capaz de hacer esas relaciones. Como no utilizábamos este módulo si no otro para hacer consultas «normales» a Redis, nos pusimos a investigar sobre ello.
Un buen primer punto de partida es esta charla de Andreas Granig, CTO y cofundador de Sipwise en el Kamailio World de 2018, ya que se trata de unos de los principales desarrolladores del módulo y está genial para entender cómo funciona:
Tras hacer pruebas en nuestro entorno de desarrollo vimos que podríamos llegar a este nuevo escenario migrando ambos módulos, dialog y location, a Redis, dejando practicamente el cluster MySQL sólo para consultas y unas pocas escrituras:
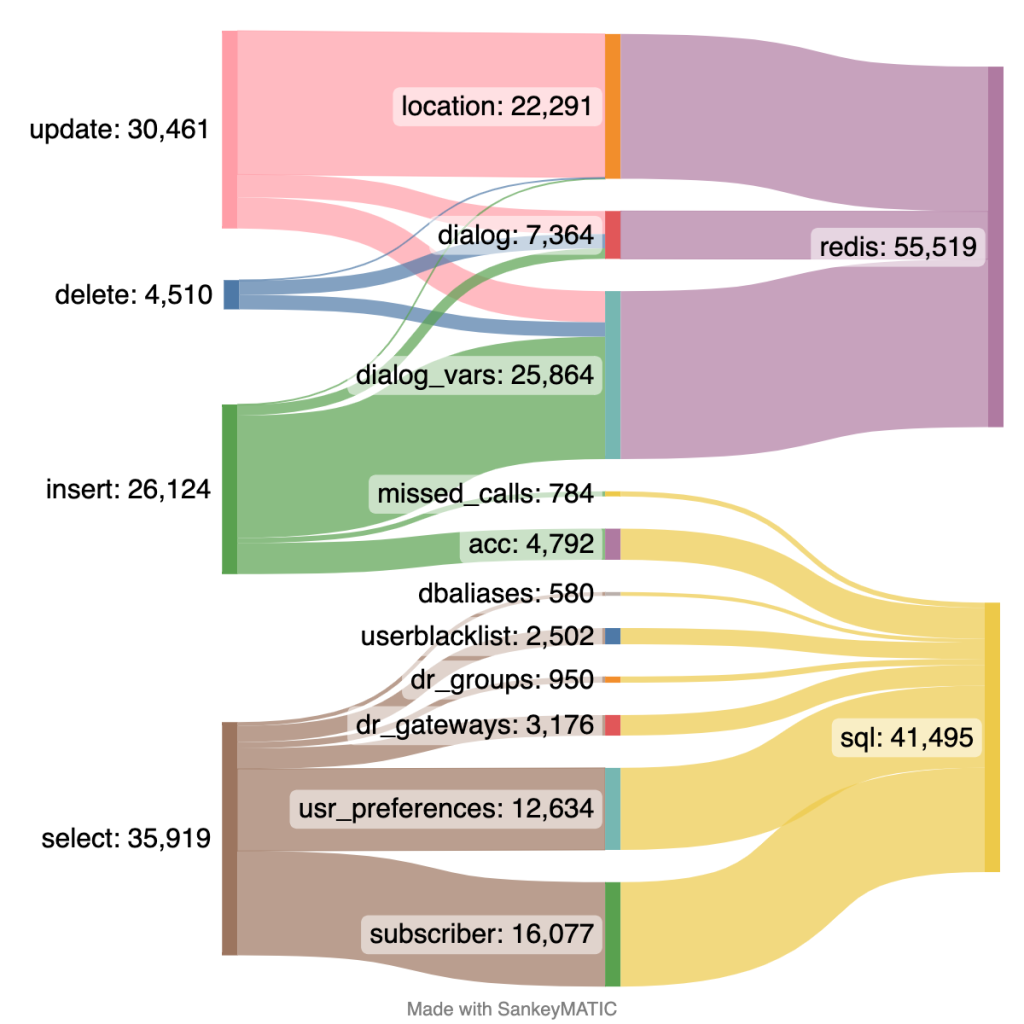
Aunque el cambio como tal en Kamailio era muy simple, teníamos que adaptar todos los scripts y la programación que funcionan por detrás del core de Sarevoz para que pudiesen utilizar Redis en vez de MySQL: métricas de usuarios registrados, control de gasto, llamadas en curso, etc.
Además también teníamos que decidir la infraestructura a montar para Redis, ya que en la actual que teníamos/tenemos, los equipos de Redis son secundarios en «read-only» y las escrituras están controladas y se realizan en un nodo aparte (Kamailio sólo usaba esos equipos de Redis para consulta). Aunque anteriormente parece que era posible (digo «posible» ya que nunca lo habíamos utilizado de esa manera) montar dos equipos de Redis en configuración principal-secundario cruzada, en la última versión ya no es posible y hay que pasar a utilizar Redis Cluster (que está más orientado al sharding de datos) o Redis Sentinel (en el que el propio Redis se encarga de mover quien es el principal).
Visto esto y conociendo la gran estabilidad de Redis:

Decidimos que cada Kamailio tendría su propio Redis (¡de vuelta al monolito!), de forma que sería una arquitectura más simple, sin complicaciones de sistemas de HA, replicaciones, etc.
Tras hacer las preparaciones necesarias en toda la parte de gestión y poder adaptarlas para una migración escalonada (queríamos evitar tener que cambiar todo de golpe), cambiamos primero la parte del módulo location y posteriormente la del módulo dialog, en distintos días, nunca en más de un equipo a la vez, y «abriendo poco a poco» el grifo de las llamadas que procesaba cada Kamailio.
Y tal y como habíamos previsto, se han reducido como pensábamos las escrituras en MySQL:

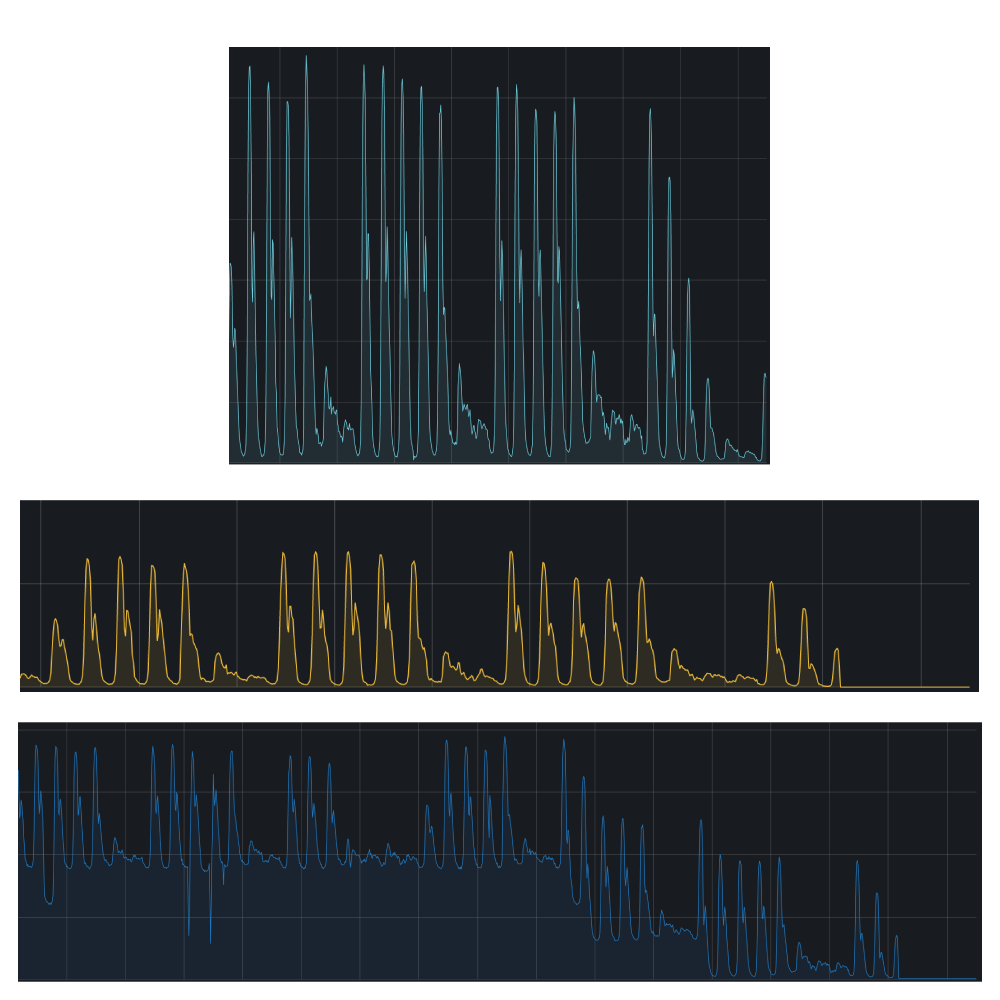
Hemos visto que el consumo de recursos de esta instancia de Redis en cada Kamailio es irrisoria (no llega a consumir ni 100MB de memoria RAM) y el rendimiento es muy superior, no es algo que hubiésemos podido hacer con MySQL.
No hay que fiarse
En Sarevoz (¡y en el resto de servicios!) tratamos con mucho cariño a nuestros servidores; siempre intentamos que estén funcionando de la forma más óptima posible, trabajando continuamente en reducir el downtime y aumentar la resilencia a fallos, pero hay veces por muchas pruebas que se hagan en entornos controlados, hasta el día que tiene carga de trabajo real no sabes lo que va a ocurrir.
No hay que fiarse de que por muy nuevo que sea algo o con mejores características, vaya a funcionar bien o mejor «porque sí», es posible que sobre el papel «en mi equipo funcione» pero el tener carga real muchas veces dista mucho de las pruebas que se hacen entornos acotados.



Enviar una respuesta
No hay comentarios