
La semana pasada leí un interesante artículo de cómo Netflix, una de las mayores empresas de contenido digital del mundo, ha conseguido rebajar de 45 minutos a 7 su tiempo máximo de tolerancia a fallos y conmutación ante una caída de una región de AWS. Me ha parecido tan interesante que voy a tratar de adaptarla a nuestro blog.
Entrada original de Amjith Ramanujam publicada en https://opensource.org
Consigue ahora tu e-book de gestión de ciberseguridad para PYMEs
Durante el invierno de 2012 Netflix sufrió una larga caída que duró siete horas, debido a problemas en el servicio de balanceo de AWS de la región US-Este de Amazon. Netflix corre sobre Amazon Web Services (AWS); no tenemos ningún CPD. Todas las interacciones con Netflix se sirven desde AWS, excepto la visualización del propio vídeo. Una vez que le das a «reproducir» los archivos de vídeo se sirven desde nuestro propio CDN. Durante esa caída nada del tráfico que iba contra la región US-Este terminaba por llegar a nuestros servicios.
Para prevenir que esto volviese a ocurrir de nuevo decidimos construir un sistema de conmutación regional, resiliente a fallos de nuestros proveedores de servicios. Un sistema de conmutación es un método para proteger sistemas de ordenadores en los que el equipamiento en standby toma el control de forma automática cuando el sistema principal falla.
La conmuntación por regiones redujo el riesgo
Nos expandimos a un total de tres regiones de AWS: dos en los Estados Unidos (US-Este y US-Oeste) y uno en la Unión Europea (EU). Tenemos reservada tanta capacidad como para poder absorber el fallo en una región.Un fallo típico tenía esta pinta:
- Te dabas cuenta de que una de las regiones estaba teniendo problemas.
- Ampliabas las otras dos regiones «salvadoras».
- Empezabas a pasar algo de tráfico de la región problemática a las salvadoras.
- Cambiabas el DNS y dejabas de utilizar la región problemática.
Vamos a ver cada paso por separado.
1. Identificar el problema
Necesitamos métricas, a poder ser una única, que nos digan el estado de salud del sistema. En Netflix utilizamos una métrica de negocio llamada «Stream Starts Per Second» (SPS), que representa el número de clientes que han empezado a reproducir un vídeo de forma satisfactoria.
Tenemos esta información particionada por región y en cualquier momento podemos pintar los datos de SPS por cada región y compararla contra el valor de SPS del día anterior y de la semana anterior. Si notamos una caída en la gráfica de SPS sabemos que nuestros clientes no están pudiendo empezar a ver nuevos vídeos y por lo tanto tenemos un problema.
El problema no tiene por qué ser un fallo en la infraestructura de la nube. Puede ser código con fallos desplegado en uno de nuestros cientos de microservicios que componen el ecosistema de Netflix, un corte de un cable submarino, etc. Podemos no saber la razón, pero simplemente sabemos que algo está mal.
Si esta caída de SPS se observa en una única región, es una gran candidata para una conmutación regional. Si la caída se observa en varias regiones no estamos de suerte ya que sólo tenemos capacidad suficiente para evacuar una región cada vez. Esta es precisamente la razón por la que realizamos el despliegue de nuestros microservicios por regiones. Si hay un problema en el despliegue, podemos evacuarlo al momento y depurar el problema más tarde. De la misma forma, queremos evitar el conmutar cuando el problema va a seguir a la redirección de tráfico (como ocurriría en un ataque DDoS).
2. Ampliar la capacidad en las regiones salvadoras
Una vez que hemos encontrado la región enferma, tenemos que preparar las otras regiones (las «salvadoras») para recibir el tráfico del enfermo. Antes de que abramos el grifo necesitamos ampliar la infraestructura de las regiones salvadoras de forma apropiada.
¿Y eso qué significa en este contexto? El patrón de tráfico de Netflix no es estático a lo largo del día. Tenemos picos de visualización, por lo general sobre las 18-19h. Pero las 18 de la tarde llega en distintos momentos en las distintas partes del mundo. Un pico de tráfico en US-Este va tres horas por delante de US-Oeste, que va ocho horas por detrás de la región de EU.
Cuando falla US-Este mandamos el tráfico del este de EEUU hacia EU y el tráfico de Sudamérica a US-Oeste. De esta forma reducimos la latencia y ofrecemos la mejor experiencia posible a nuestros clientes.
Teniendo esto en cuenta, podemos utilizar una regresión lineal para predecir el tráfico que será rutado a las regiones salvadoras en ese momento del día (cualquier día de la semana) usando el comportamiento de escalado histórico de cada microservicio.
Una vez que hemos determinado el tamaño correcto de cada microservicio, desencadenamos el escalado para cada uno de ellos en el tamaño de clúster deseado y dejamos que AWS haga su magia.
3. Pasar tráfico a otras regiones
Ahora que tenemos los clústeres de microservicios con capacidad, podemos empezar a pasar tráfico de la región con problemas a las regiones salvadoras. En Netflix hemos construido un proxy trans-regional frontera de alta capacidad llamado Zuul, el cual hemos liberado con una licencia abierta.
Estos servicios de proxy están diseñados para autenticar peticiones, balanceo de carga, volver a probar peticiones fallidas, etc… El proxy Zuul además puede hacer de proxy entre distintas regiones. Utilizamos esta funcionalidad para rutar una porción del tráfico de la zona con problemas hasta que, de forma progresiva, aumentamos el tráfico rutado hasta el 100%.
Este reenvío de tráfico de forma progresiva permite a nuestros servicios utilizar sus propias políticas de escalado para hacer cualquier tipo de escalado reactivo que vean necesario para poder encargarse del tráfico entrante. Esto lo hacemos para compensar cualquier cambio en el volumen de tráfico entre cuando hicimos las predicciones de escalado y lo que le ha costado a cada clúster escalar.
Zuul se encarga del trabajo duro en este punto para reenviar el tráfico de la zona con problemas a las que están funcionando correctamente. Pero llega un punto en el que tenemos que dejar de utilizar la sesión por completo. Aquí es cuando entran en juego los cambios en la DNS.
4. Cambio de DNS final
El último paso en la conmutación es cambiar los registros DNS que apuntaban a la zona afectada y redirigirlos a las zonas que funcionan bien. Esto va a quitar completamente el tráfico a la zona con problemas. Cualquier cliente que no haya expirado su caché de DNS será rutado igualmente por la capa de Zuul de la zona afectada.
Esta es la información de fondo de cómo solían funcionar las conmutaciones en Netflix. Este proceso tardaba mucho tiempo en completarse, unos 45 minutos (en un día bueno).
Acelerando la respuesta con nuevos procesos
Nos dimos cuenta de que la mayoría del tiempo (aproximadamente 35 minutos) se nos iba esperando a que las regiones salvadoras escalasen. A pesar de que AWS podía provisionar nuevas instancias en cuestión de minutos, arrancar los procesos, hacer el arranque en caliente bajo demanda y gestionar las otras tareas de inicio antes de registrarse como «UP» en el servicio de descubrimiento dominaba el tiempo de escalado.Decidimos que esto duraba demasiado. Queríamos que nuestras conmutaciones estuvieran completadas en unos 10 minutos, que además no costasen más gestión a los operadores de los servicios y que fuese neutral a nivel de presupuesto.
Reservamos capacidad en las tres regiones para poder absorber el tráfico de las conmutaciones, si ya estamos pagando por esa capacidad, ¿por qué no usarla? Así empezó el Proyecto Nimble.
Nuestra Idea era mantener un grupo de instancias sin utilizar para cada microservicio. Cuando estuviésemos listos para realizar la conmutación simplemente meteríamos nuestro «hot standby» en los clústeres para que empezasen a coger tráfico real.
A la capacidad reservada sin utilizar se le llama mínima. Algunos equipos de Netflix utilizan parte de esta capacidad mínima para ejecutar tareas por lotes, así que no podemos simplemente pasar todas las instancias a «hot standby«. En su lugar, mantenemos un clúster «en la sombra» por cada microservicio que tenemos y lo abastecemos con suficientes instancias como para acoger el tráfico de la conmutación. El resto de las instancias están disponibles para los trabajos por lotes.
En el momento de la conmutación, en vez del escalado tradicional que desencadena AWS para que nos provisione instancias, inyectamos instancias del «clúster en la sombra» en el clúster en funcionamiento. Este proceso tarda unos cuatro minutos, en vez de los 35 que tardaba anteriormente.
Como nuestra capacidad de inyección es ágil, no tenemos que ir pasando el tráfico poco a poco hasta que las políticas de escalado hayan reaccionado. Simplemente podemos cambiar las DNS y abrir las compuertas, ganando algunos minutos más durante una interrupción de servicio.
Hemos añadido filtros a los clústeres «en la sombra» para prevenir que instancias «oscuras» nos manden métricas. Ya que si no, nos «ensuciarían» las métricas y confundirían su operación normal.
También hemos parado que las instancias de los clústeres «en la sombra» se registren como «UP» en el servicio de descubrimiento modificando nuestro cliente. Estas instancias van a seguir permaneciendo en la sombra (broma totalmente intencionada) hasta que desencadenemos una conmutación.
Ahora tenemos la capacidad de hacer conmutaciones entre regiones en siete minutos. Como utilizamos nuestra capacidad en reserva, no añadimos costes de infraestructura extra. Todo este software de orquestación de conmutación está escrito en Python por un equipo de tres ingenieros.
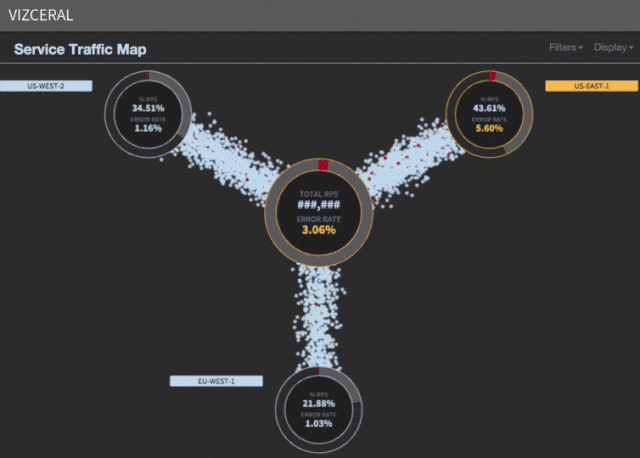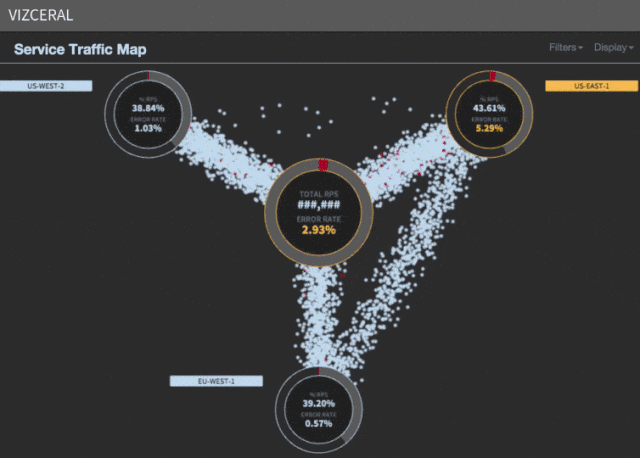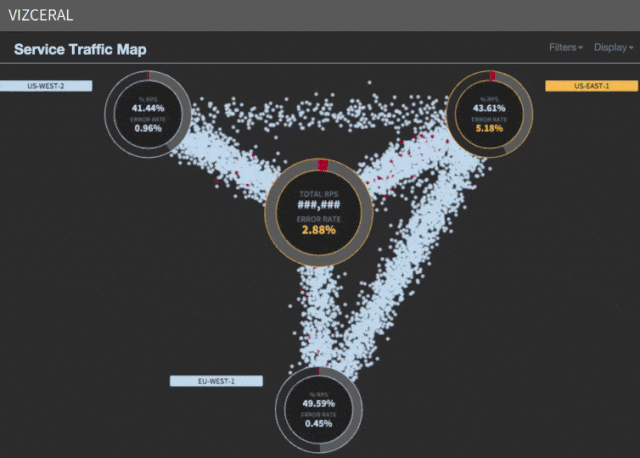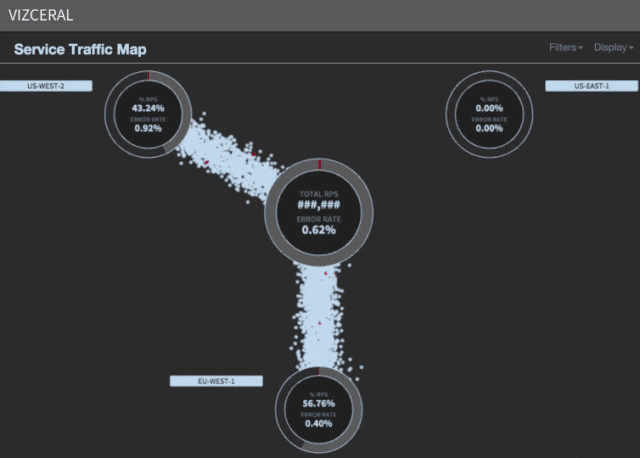
La verdad es que la entrada explica muy bien el día a día de un ingeniero de sistemas o de SRE (Site Reliability Engineer).
Podemos ver cómo las arquitecturas de microservicios están a la orden del día y muchas veces son algo totalmente necesario para poder construir sistemas IT escalables y con una tolerancia a fallos que nos asegura una alta disponibilidad más que aceptable.
Como ya comentamos cuando hablamos de lo que cuesta tener un sistema el 100% online, Netflix podría dar servicio con prácticamente 1/3 menos de los costes actuales, pero eso le dejaría desnudo ante un problema global sin capacidad de absorber el tráfico de sus usuarios y prefiere pagar ese extra y tener la seguridad de que da servicios a sus usuarios. Y no sólo es «echar dinero» en el saco del proveedor, en este caso por mucho que pagase Netflix había unos procesos que eran imposibles de acelerar.
Además podemos ver cómo Netflix tiene una buena política de respaldo y, aunque aquí no lo comentan, las prueban: tiene procesos que, de forma aleatoria, apagan servicios en producción , desde un simple proceso, a un servidor, a un clúster de un servicio completo o hasta un CPD para comprobar sus sistemas de respaldo, su famosa armada de simios. Ya os hablaré de ella en otra entrada.

Imagen del titulo: Florida Memory, publicado por Dade County Newsdealers Supply Co. bajo licencia de dominio público.
Resto de imágenes: Opensource.com bajo licencia CC BY-SA 4.0



1 Comentario
Puedes enviar comentarios en este post.
[…] arquitectura que utilice ambos sistemas, en lo que se denomina un modelo de Cloud híbrido. Esto es por ejemplo lo que emplea Netflix: tiene sus propios equipos para servir contenido pero utiliza Clouds públicos para servir su […]
Cloud público, privado o híbrido: ¿qué conviene a tu negocio? | Blog Sarenet 5 años ago
Enviar una respuesta
No hay comentarios