
En la anterior entrada sobre documentación con control de versiones comentaba la necesidad de utilizar un sistema de control de versiones, en esta nueva entrada voy a intentar arrojar un poco de luz y a enseñar lo básico para empezar a utilizar estos sistemas, en concreto Git. Al igual que la anterior, será una entrada bastante técnica.
¿Qué es y para qué sirve un sistema de control de versiones?
Cuando se trabaja en programación es habitual tanto el hacer modificaciones como el que estos cambios los haga más de una persona. Para ello surgieron los sistemas de control de versiones que, como norma general, se encargan de guardar cada cambio, fecha y persona que lo ha hecho para poder hacer una revisión y comparación de los mismos a posteriori.
Como con todo, han ido surgiendo bastantes tipos de sistemas a lo largo del tiempo, tanto centralizados (todos los cambios se guardan en un servidor central) como distribuidos (todo el mundo que trabaja en el proyecto tiene la copia completa), así como de pago, libres y gratuitos: Git, Subversion, Mercurial, Bazaar, CVS, Darcs…
El que nos ocupa en este post es Git, que se trata de un control de versiones distribuido y libre. ¿Y por qué Git? Git es el sistema que se utiliza para gestionar el código de Linux (el núcleo), y se desarrolló específicamente para ese cometido. Ha tenido su boom con sitios como GitHub donde podemos ver que desde la NASA hasta Disney pasando por la Casa Blanca comparten sus desarrollos de código.
Pero a pesar de lo extendido que está, su curva de aprendizaje es bastante grande. Sobre todo si se viene de otros sistemas centralizados como por ejemplo SVN. Por este motivo, voy a intentar explicar las tareas más habituales a la hora de trabajar con Git. Si bien hay bastantes herramientas para gestionar un repositorio Git mediante una interfaz para aprender los conceptos básicos, nada mejor que la vieja y confiable línea de comandos.
Yo vengo de trabajar con SVN por lo que posiblemente veas que esta introducción se parece al flujo de trabajo de SVN pero con los comandos básicos de Git.
Así se trabaja en Git
El flujo de trabajo general en Git sería el siguiente:
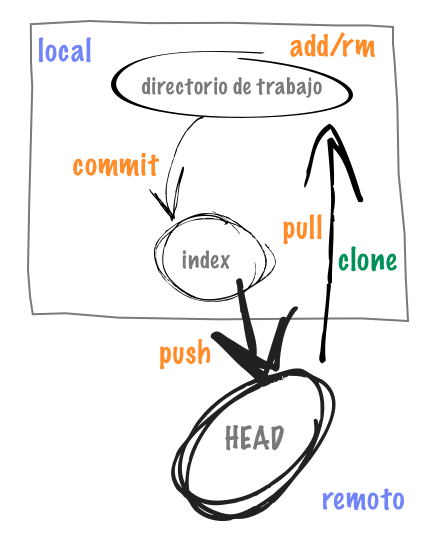
Parece complejo, ¿verdad? Vamos a verlo poco a poco.
Creación/inicialización/clonado de un repositorio
Lo primero que necesitamos hacer es conseguir un repositorio: Aquí hay varias opciones, sobre todo dependiendo de si vamos a trabajar contra un repositorio que ya existe o si empezamos desde cero.
Si queremos inicializar un repositorio tenemos que usar simplemente init:
$ git init test-repo Initialized empty Git repository in /Users/koldo/Proyectos/git/test-repo/.git/
Si por el contrario queremos clonar un repositorio, tenemos que usar el comando clone, que descargará todo el repositorio:
$ git clone https://github.com/badcrc/signtophia_x.git Cloning into 'signtophia_x'... remote: Counting objects: 108, done. remote: Total 108 (delta 0), reused 0 (delta 0), pack-reused 108 Receiving objects: 100% (108/108), 4.06 MiB | 582.00 KiB/s, done. Resolving deltas: 100% (9/9), done. Checking connectivity... done.
Una vez hecho esto entramos en la carpeta y ya tendremos en nuestro ordenador nuestro «directorio de trabajo», en él habrá un directorio «.git» que contiene toda la meta-información sobre el repositorio.
Realizar cambios
Ya tenemos el repositorio en nuestro ordenador y hemos modificado algunos archivos, tendremos que añadir esos archivos, primero al index y luego al head, para ello utilizamos el comando add (o rm si hemos borrado un archivo):
$ git add src/include/header.php $ git rm src/include/header.php
Podemos añadir/quitar tantos archivos como queramos, ahora hacemos un commit de los mismos, que no los pasa al repositorio como ocurre en SVN, sino que aún nos quedaría un paso más ya que el commit lo que hace es pasarlo a una zona de stagging (index):
$ git commit -m 'esto es una prueba' [master f8a9589] esto es una prueba 1 file changed, 0 insertions(+), 0 deletions(-) create mode 100644 zzz
En el commit se especifica el comentario del mismo, e incluye todos los archivos modificados hasta ahora.
Ahora podríamos seguir trabajando y seguir haciendo commits pero si hay más gente trabajando en este mismo repositorio aún no tendrían los cambios, para eso hacemos un push. El comando completo git push origin HEAD pero como por normal general solemos usar HEAD (el tope de la rama actual), se configura esta alias.
$ git push Counting objects: 6, done. Delta compression using up to 4 threads. Compressing objects: 100% (6/6), done. Writing objects: 100% (6/6), 489 bytes | 0 bytes/s, done. Total 6 (delta 4), reused 0 (delta 0) To git@github.com:badcrc/signtophia_x.git c3035d9..35373ab master -> master
Con esto si alguien clona el repositorio o lo actualiza tendrá ya nuestros últimos cambios (y en caso de fuego, ya podemos abandonar el edificio).

Trabajando con más gente
Como comentaba antes, lo normal es utilizar Git para trabajar en proyectos con más gente, para este ejemplo suponemos que ya existe un repositorio y lo tenemos clonado.
Lo primero cuando empezamos a trabajar en un repositorio es actualizarlo por si alguien ha hecho cambios. Git utiliza el concepto de pull/push para recoger los cambios (ya hemos visto que push era para enviarlo).
Al hacer el pull veremos tanto los cambios como los archivos creados y eliminados (la salida de este comando esta editada para no poner un churro enorme):
$ git pull remote: Counting objects: 397, done. remote: Compressing objects: 100% (217/217), done. remote: Total 397 (delta 173), reused 341 (delta 156) Receiving objects: 100% (397/397), 150.28 KiB | 0 bytes/s, done. Resolving deltas: 100% (173/173), done. From github.com.:badcrc/puppet-modules 1bed3bb..b9d18c8 master -> origin/master * [new branch] library -> origin/library Updating 1bed3bb..b9d18c8 Fast-forward albergue/manifests/init.pp | 48 +- apache/manifests/init.pp | 57 +- apache/manifests/vhost.pp | 35 ++ apache/templates/sysconfig.httpd.conf.erb | 31 + apache/templates/virtualhost/vhost.conf.erb | 116 ++++ haproxy/templates/haproxy-base.cfg.erb | 4 +- letsencrypt/manifests/certonly.pp | 9 +- letsencrypt/manifests/init.pp | 10 +- mysql/manifests/server/account_security.pp | 2 + netdata/manifests/init.pp | 14 +- netdata/manifests/install.pp | 32 +- nginx/templates/nginx.service.erb | 15 +- php/manifests/packages.pp | 2 +- wordpress/templates/wordpress-site.conf.erb | 40 +- yum/manifests/repo/rpmforge.pp | 4 +- 63 files changed, 8398 insertions(+), 173 deletions(-) create mode 100644 apache/templates/01-ssl.conf.erb create mode 100644 netdata/templates/netdata.conf.erb create mode 100644 netdata/templates/slack.alert.sh.erb
De esta forma ya podemos empezar a trabajar con los cambios que ha ido haciendo la gente mientras no trabajábamos nosotros.
Comandos adicionales
Un par de comandos muy útiles son status y diff. Con el primero veremos los archivos que hemos modificado y de los cuales aún no hemos hecho commit, es un comando muy «socorrido» y te verás teclearlo muchas veces cuando pienses que el perro se ha comido tus commits:
$ git status On branch master Your branch is up-to-date with 'origin/master'. Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git checkout -- <file>..." to discard changes in working directory) modified: apache/spec/acceptance/nodesets/default.yml no changes added to commit (use "git add" and/or "git commit -a")
Y con diff podemos ver las diferencias que existen:
$ git diff apache/spec/acceptance/nodesets/default.yml diff --git a/apache/spec/acceptance/nodesets/default.yml b/apache/spec/acceptance/nodesets/default.yml index 05540ed..82b8eaa 100644 --- a/apache/spec/acceptance/nodesets/default.yml +++ b/apache/spec/acceptance/nodesets/default.yml @@ -1,5 +1,5 @@ HOSTS: - centos-64-x64: + centos-64-x64: roles: - master platform: el-6-x86_64
¿Y qué es eso de Pull Request?
Posiblemente si estás leyendo esto te suene o hayas escuchado Pull Request o PR. Esto es «terminología» de Github (en Gitlab tiene otro nombre) pero viene a ser que si estás trabajando en un repositorio de otra persona para el que no tienes permisos de push, le mandas los cambios desde una versión tuya (un fork) para que los revise y los incluya.
Resumiendo…
Con esta pequeña introducción ya deberíamos ser capaces de empezar a utilizar Git o por lo menos a que nos suenen sus conceptos. Git es muy complejo y se pueden llevar a cabo muchas tareas (ramas, rebases, merges, .gitignores, etc), dejo algunos enlaces para quien quiera investigar más en el tema:
- Charla de Linus Torsvadls en Google sobre Git: Linus Torvalds & git
- Git – the simple guide
- Git en 15 minutos: Try Git
- Documentación oficial de Git



2 Comentarios
Puedes enviar comentarios en este post.
[…] las comillas) un lugar donde poder alojar código mediante el sistema de control de versiones Git, […]
Microsoft sigue apostando por el software libre: todas las claves de la compra de GitHub | Blog Sarenet 8 años ago
[…] no es fácil como se pudo ver en la introducción al mismo que escribí hace unos años, aunque puedes sobrevivir y utilizarlo únicamente desde consola, ciertas acciones […]
Extensiones de VSCode sin las que no puedo vivir | Blog Sarenet 5 años ago
Enviar una respuesta
No hay comentarios